Aurora Multi-Master 解读
Aurora Multi-Master 解读
1.Aurora官方资料
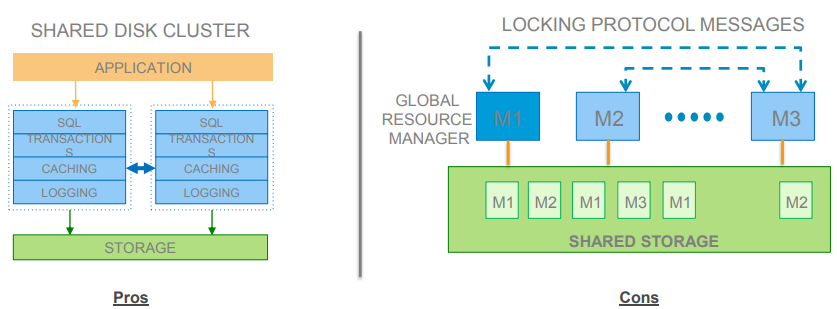
1.1 分布式锁管理(未采用)
优点:
- 数据对于所有节点可用
- 容易搭建上层应用
- 类似于多处理器中的缓存一致性
缺点:
- 基于每个锁,加重缓存一致性通信
- 网络代价昂贵
- 当热点块产生会有负影响
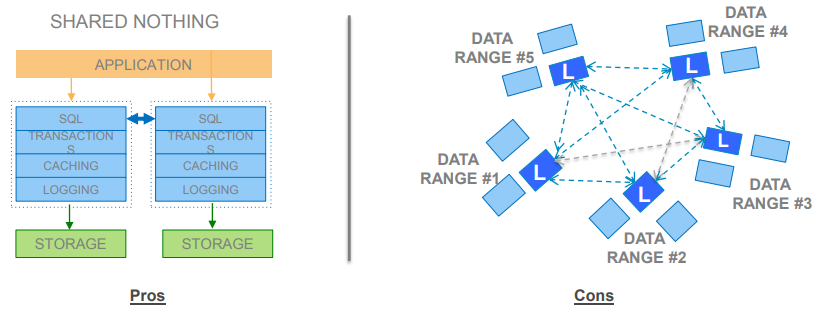
1.2 2PC或Paxos实现一致性(未采用)
优点:
- Query可以分解并发送到数据节点
- 对于提交,更少一致性通信(在事务提交时才进行冲突检测和解决)
- 能够扩展到多个节点
缺点:
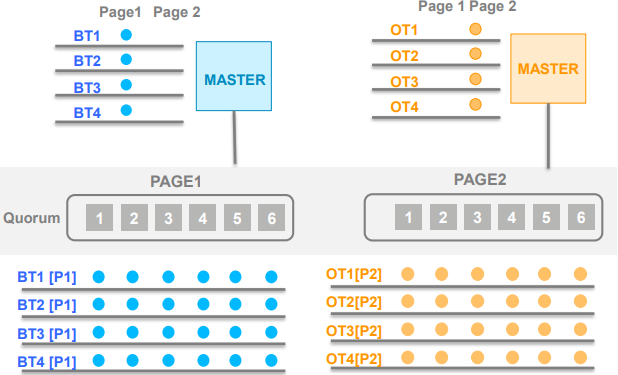
- Aurora有很多一致性的”绿洲”
- 数据库节点(CE)可以从那个节点获知事务的顺序。
- 存储节点(SE)可以从那个节点获知事务应用顺序。
- 只有当数据在多个数据库节点和多个存储节点同时改变存在冲突
- 不需要大的协调。
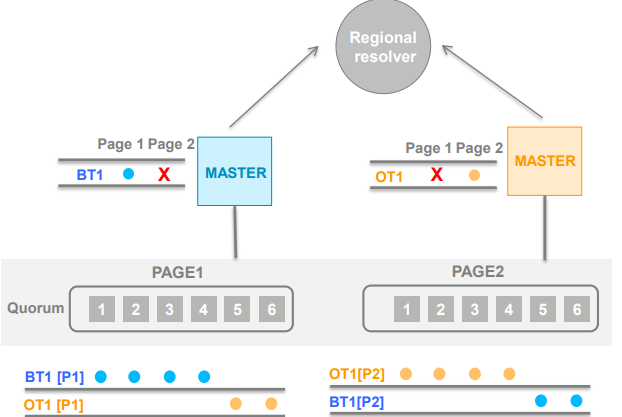
1.4 分层解决冲突
- 两个主节点同时写入Page 1和Page 2
- 蓝色主节点在P1 赢下仲裁,橙色主节点在P2赢下仲裁
- 两个节点意识到冲突并开始两种选择:回滚这个事务 或 向上层提交给区域仲裁
- 仲裁人决定谁赢得这次仲裁。
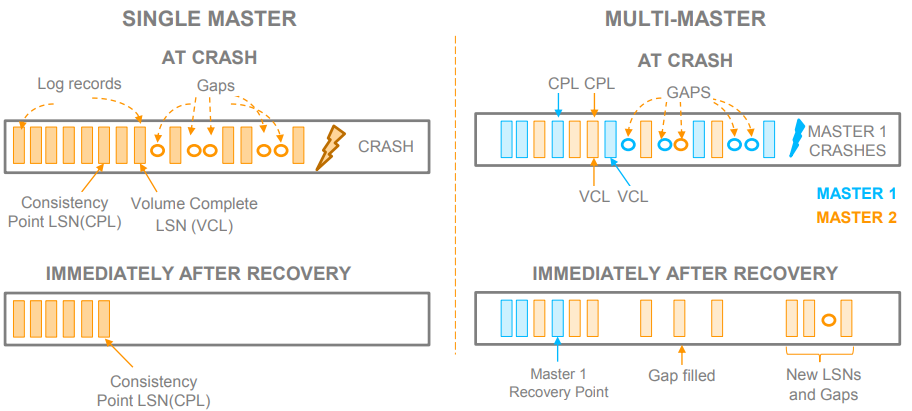
1.5 多主机的崩溃恢复
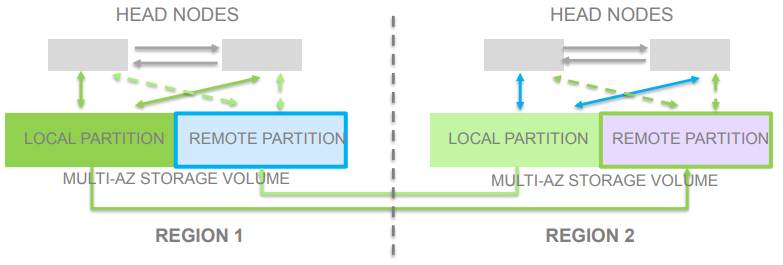
1.6 多区域多主机
- 本地接收写
- 乐观并发控制——没有分布式锁管理,没有繁琐的锁管理协议
- 在头结点,存储节点,在AZ和region级别实现仲裁制度
- 如果没有或者只有低等级冲突可以保证接近线性扩展的性能。
2.行业解读
2.1 解读一
每个master维护自己的lsn
- 从全局看,每个参与多写的计算节点(主CE)都有逻辑的Master。每个计算节点维护自己的LSN,CPL和VCL。如果一个计算节点挂掉重启,那他只恢复自己的CPL并rollback自己(Version > CPL)的redolog。
- 到每个segment上,写到每个segment的每条redo MTR记录,ID为 [
计算节点ID,计算节点private LSN] 的Pair。2.1 解读二
分布式Log
distributed log一般用的是类似于经典的Quorum consensus算法,就是2W>N && W+R>N,但是有细微的改动,也有很优越的好处:strip。
2.3 解读三
当这个Master crash的时候,新的Master是不是需要从distributed ledger找到旧Master的VDL,进而trucate掉该系列LSN中大于VDL的redo?下面是ppt的其中一页:
多个Master之间的冲突检测和解决是比较简单的,也是得益于distributed ledger。只要Master的redo log带上page修改前的version,distributed ledger做一个CAS就能发现冲突了。那发现冲突后怎么解决呢?比如T1和T2两个事务冲突了,最简单的做法就是一起回滚,但是Aurora实现了仲裁者,可以由仲裁者来觉得谁回滚,具体实现就不清楚。